
Software and human call processing have significant differences for businesses who rely on the accuracy of phone call information.
The difference between software speech analytics and human call processing is wide, but there are improvements. Technology has come a long way in the past 40 years making enormous leaps in speech analytics. Companies that find the newest system are quick to patent and secure their advances as the demand for speech-enabled devices grows year after year. Mobile devices are increasingly adding advanced speech analytics to enhance productivity, make driving safer, and texting hands-free.
The goal of speech analytics for businesses is to affordably identify what happened on a phone call, if the caller a missed opportunity, and what this information can do to help both marketing and sales closing going forward. The goal of the patent creators is to be a little more accurate and have fewer errors than their competitors to have a superior product. These goals clash with the largest innovators of speech analytics technology whose goal is to make speech analytics better than human processing.
There are three major problems that software speech analytics has to overcome: background noise, echo or reverberation, and the accent or dialect variations. Major scientific theories, algorithms, and models have taken shape around advances in modern computing allowing innovative ideas to finally become a reality. In the following sections, we will discuss these three major problems that you should consider if you are interested in call processing.
To properly discuss how the differences impact businesses who utilize speech analytics to score and process phone calls we need to know their WER. The Word Error Rate (WER) is a standardized model of assessing how well software performs at speech analytics. “The word error rate (WER) is a good measure of the performance of dictation system, and a reasonable approximation of the success of a voice search system.” – Senior
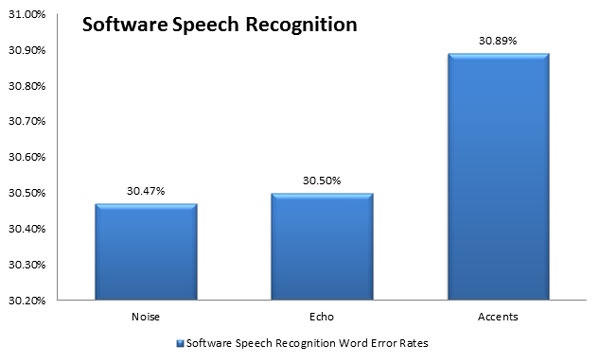
1. Background Noise: How well do Apple, Google, and Microsoft perform?
Figure 1.

Background noise is a contributing factor to the ability to clearly and accurately transcribe a conversation during a phone call. Sources of noise include wind, crowds, music, and even screaming children. Ideally, a phone call is placed by the caller in a quiet place where they can think and talk coherently.
That’s not always the case.
Looking above at figure 1, the ability for software speech analytics to accurately translate what is being said by the caller in noisy environments corresponds to high WER, or high error rates. When the caller knows that they have difficulty being heard by the person on the other side of the line, they will attempt to compensate, and this is called the Lombard effect. The Lombard effect often makes software recognition even more difficult because the caller’s speech fluctuates:
- The loudness of the caller’s voice goes up and down.
- Pitch changes in the caller’s voice.
- The harmonic rate of words changes for the caller.
- The duration and pausing of syllable intensity shifts for the caller.
The big takeaway of whether or not noise is a consideration for you and your business is how often has noise impacted your companies calls in the past, and what are you going to do about it?
“Results of our study shows that performance of cloud-based speech analytics systems can be affected by jitter and packet loss; which are commonly occurring over WiFi and cellular and mobile network connections.” – Assefi
If even 25% of your businesses phone calls occur from cell phones, your business has been negatively impacted by noise in some degree – but it is ultimately up to you to put a dollar value on that expense. Having human call processing analysts screen and listen to your calls is one way to mitigate the factor of noise in calls.
2. Echo and Reverberation: Building Robust Call Handling Systems

Source: https://www.kirtland.af.mil/News/Photos/igphoto/2000429478/
Software speech analytics software must account for the direction of the voice. A simple way to understand this problem is to carry on a conversation in an empty and hardwood floored house. If you start to hear your voice echo off the walls and floor, it interrupts what you are saying. In the image above, the Airforce tests echo and reverberation in an echo-free room. As you can see, people typically won’t be calling your business from this type of place.
Imagine how difficult it would be to hear someone’s voice with an echo also being picked up by the phone microphone and relayed over the call. Hello… hello… hello…
The best takeaway from echo and reverberation I can give you is that to train software on how to account for the doubling effect of sounds from echo, recordings of human scored calls are used over and over again, every single day to add to training data. As of today, software is 100% dependent upon calls that were already scored by humans to raise their day-to-day accuracy of phone call transcriptions using these steps:
- A human call analyst is used to evaluate how well a system is at diagnosing echo and sound reverberation in the caller’s environment.
- After the phone call has been scored and transcribed by a human call analyst, the information is added to software speech analytics training data.
- The speech software will then attempt to transcribe the call and differences between the human transcription and the software transcription produces a WER rate.
- Rinse and repeat… over and over again millions of times to lower the average WER rate.
Human call analysts are trained and vetted using a similar school of thought using these steps:
- Human call analysts vetted with years of call handling experience are put through a school with hours of training with typical calls, difficult calls, and how to avoid word errors.
- CallSource human call analysts are given amazing opportunities to work from their chosen locations, they are screened and trained on the best practices in the industry and are motivated to improve their accuracy rates continually.
- Once human call analysts are certified, they begin taking phone calls and work with mentors and colleagues to ensure that processes are being followed.
- Rinse and repeat… on their schedule, delivering the lowest WER rates in the industry.
“The network must not only learn how to recognize speech sounds, but how to transform them into letters, this is challenging, especially in an orthographically irregular language like English.” – Alex Graves
Graves (quoted above) has researched for improving models of speech analytics with neural networks and gives insight into how speech analytics output can defer in decoding single sentences:
Example #1
Speaker: TO ILLUSTRATE THE POINT A PROMINENT MIDDLE EAST ANALYST IN WASHINGTON RESOUNDTS A CALL FROM ON CAMPAIGN.
Speech Recognition Software: TWO ALSTRAIT THE POINT A PROMINENT MIDILLE EAST ANALYST IM WASHINGTON RECOUNCACALL FROM ONE CAMPAIGN.
Example #2
Speaker: ALL THE EQUITY RAISING IN MILAN GAVE THAT STOCK MARKET INDIGESTION LAST YEAR.
Speech Recognition Software: ALL THE EQUITY RAISING IN MULONG GAVE THAT STACKR MARKET IN JUSTIAN LAST YEAR.
Source: Towards End-to-End Speech Recognition with Recurrent Neural Networks by Alex Graves
Both software speech analytics and human call analysts require robust systems to ensure that WER rates are as low as possible. WER rates directly contribute to businesses missing phone calls and misunderstanding what actually happened on phone calls. End to end speech software struggles to deal with echo and state of the art solutions continue to fall short the worse the noise and echo are in the environment of the caller.
3. Accents and Dialects: The curveball of call handling
Source: https://giphy.com/gifs/XEde2IUYpj3Hi/html5
According to Wikipedia, the United States has over 30 major dialects of the English language. For native-born Americans, these apply to the geographic location you are born and raised, but also to the dialects of your parents. Assuming that all of your business calls are from callers with a dialect that software has trained on, you should be looking a moderately high but acceptable WER rate for accents. The diversity of your callers weighs heavily on the accuracy outcomes of speech analytics WER rates. You would see a shocking rise in WER rates for callers that come from a distinct dialect or who carry a unique accent separate from what the software has been training on.
“The performance of speech analytics systems degrades when speaker accent is different from that in the training set. Accent-independent or accent-dependent recognition both require collection of more training data.” – Kiu Wai Kat
Accents and dialects represent a curve, such as a curveball, as utterances are spoken, and software attempts to accurately decode the words into coherent sentences. The degrading accuracy rates contribute to large gaps and word errors which may completely miss what was said or intended. When the outcome of what happened is dependent on a single word… and that word is usually interpreted incorrectly; the consequences are detrimental for businesses.
All of the large studies on accents point out that speech analytics has been unable to conquer the British English speech systems of Scotland, and with hilarious results (see the video below, video contains adult humor)
Source: BBC Scotland, https://www.bbc.co.uk/programmes/p00hbfjw
Only small progress has been made in dealing with different dialects and accents as these interrupt the way that words sound to software speech analytics. The systematic approach required for robust software speech analytics is challenged by the need for a system that is adaptable to a large variance of pronunciation.
Human call analysts also struggle with accents and dialects unfamiliar to them. However, one huge advantage that CallSource has is to select and hire human analysts who are familiar with those accents. There are call analysts who understand large sets of accents and dialects with ease and they are fully capable of the challenge.
“The error rate from accent speakers is around 30.89%” – Liu Wai Kat
The quantifiable reasons that accents are difficult to classify, transcribe and decode have to do with the acoustic differences between accent groups. Those differences are difficult to account for while still accounting for noise and echo in the environment. For ESL (English as a second language) speakers who have thicker accents, the problems are compounded if they are not in ideally quiet and low echo environments.
The detection of key phrases during a call is vitally important to understanding what happened during a call. How those key phrases are used is how that call will ultimately be classified by the system. Marketing and sales are unable to move forward effectively without accurate information of what happened during an initial phone call into the business. Advances in the improvement of accents will have to be developed in every accent and dialect individually and added to training data collectively to overcome the problem of high WER rates.
Conclusion
You should ask yourself: are you clever enough to handle high phone call accuracy rates? Can you make a difference in your business by knowing what happened on every single call? Can you achieve the results you need even with pages of word errors?
We think you are clever.
We know that you could turn that knowledge into practical business decisions for the future, and by those decisions, you can make waves in your market. Assuming you do not want to deal with all of these issues, just go back to doing what you do best:
- Asking the caller to call you back from a quieter place over 30% of the time.
- Asking the caller to move into a room with fewer echoes over 30% of the time.
- Having to task a sales or service employee to re-listen to 30% of phone calls from a region with specific accents.
- Asking the caller to call you back from a landline or a location with better reception.
Figure 2.
The differences between software-based speech analytics and human call analysts comes down to how much of an impact accuracy makes in your business. Talk to your appointment setters and ask them if they ever have trouble hearing what people are saying because it’s a good bet that if they have ever had trouble, your call processing has had trouble.
Learn more about CallSource’s Human Call Processing and Monitoring Services
Article References
- Assefi, Mehdi, et al. “An Experimental Evaluation of Apple Siri and Google Speech analytics.” An Experimental Evaluation of Apple Siri and Google Speech analytics, www.cs.montana.edu/izurieta/pubs/sede2_2015.pdf.
- Hannun, Awni, et al. “Deep Speech: Scaling up End-to-End Speech analytics.” [1412.5567] Deep Speech: Scaling up End-to-End Speech analytics, 19 Dec. 2014, arxiv.org/abs/1412.5567.
- Kat, Liu Wai, and P. Fung. “Fast Accent Identification and Accented Speech analytics.” 1999 IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings. ICASSP99 (Cat. No.99CH36258), 1999, doi:10.1109/icassp.1999.758102.
- Senior, Andrew, et al. “An Empirical Study of Learning Rates in Deep Neural Networks for Speech analytics.” An Empirical Study of Learning Rates in Deep Neural Networks for Speech analytics – IEEE Conference Publication, 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, ieeexplore.ieee.org/document/6638963/.
- Xuedong Huang, James Baker, and Raj Reddy. 2014. A historical perspective of speech analytics. Commun. ACM 57, 1 (January 2014), 94-103. DOI: https://doi.org/10.1145/2500887
- Zhang, Ying, et al. “Towards End-to-End Speech analytics with Deep Convolutional Neural Networks.” [1701.02720] Towards End-to-End Speech analytics with Deep Convolutional Neural Networks, Cornell University, 10 Jan. 2017, arxiv.org/abs/1701.02720.